

“Hate speech” is a subjective term that is used to silence dissent, criticism, and politically incorrect opinions and information. The Supreme Court of The United States ruled unanimously, that “hate speech” is free speech. Our tech overlords in Silicon Valley don’t see things that same way. Their supreme rulers use “hate speech” to silence political dissidents, stifle market competition, and prevent uncomfortable truths from surfacing on the normie web.
A company called Hatebase–based in Canada–is using their technology and human input to help governments, tech companies, academics and more to detect “hate speech.” “Hate speech” is subjective. Those in power decide what it is and how to police it. Hatebase admits this. Ironically their biggest source of “hate speech” is Twitter. Yet you’ll still find Twitter on both App Stores, while Gab’s apps have been banned for–you guessed it: “hate speech.”
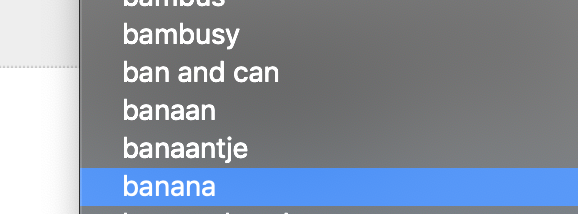
Their database of “hate speech” words is also hilarious and shows why this type of approach to policing content online is a joke. It includes terms like “banana” and “tiger.”

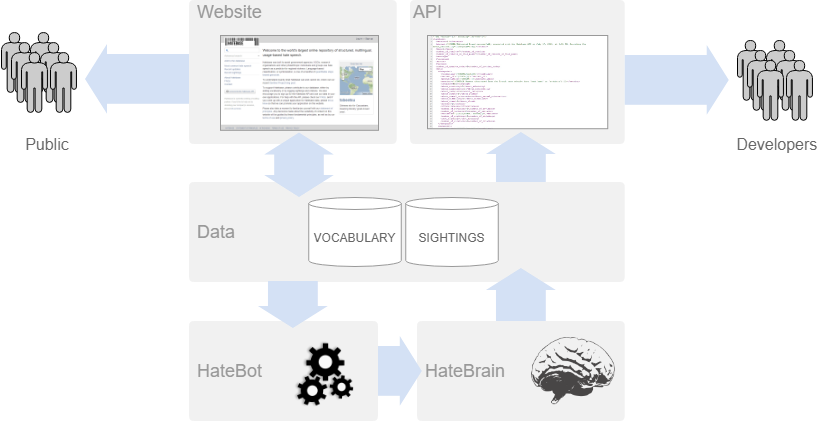
Policing hate speech is something nearly every online communication platform struggles with. Because to police it, you must detect it; and to detect it, you must understand it. Hatebase is a company that has made understanding hate speech its primary mission, and it provides that understanding as a service — an increasingly valuable one.
Essentially Hatebase analyzes language use on the web, structures and contextualizes the resulting data, and sells (or provides) the resulting database to companies and researchers that don’t have the expertise to do this themselves.
The Canadian company, a small but growing operation, emerged out of research at the Sentinel Project into predicting and preventing atrocities based on analyzing the language used in a conflict-ridden region.
“What Sentinel discovered was that hate speech tends to precede escalation of these conflicts,” explained Timothy Quinn, founder and CEO of Hatebase. “I partnered with them to build Hatebase as a pilot project — basically a lexicon of multilingual hate speech. What surprised us was that a lot of other NGOs [non-governmental organizations] started using our data for the same purpose. Then we started getting a lot of commercial entities using our data. So last year we decided to spin it out as a startup.”
You might be thinking, “what’s so hard about detecting a handful ethnic slurs and hateful phrases?” And sure, anyone can tell you (perhaps reluctantly) the most common slurs and offensive things to say — in their language… that they know of. There’s much more to hate speech than just a couple ugly words. It’s an entire genre of slang, and the slang of a single language would fill a dictionary. What about the slang of all languages?
A shifting lexicon
As Victor Hugo pointed out in Les Miserables, slang (or “argot” in French) is the most mutable part of any language. These words can be “solitary, barbarous, sometimes hideous words… Argot, being the idiom of corruption, is easily corrupted. Moreover, as it always seeks disguise so soon as it perceives it is understood, it transforms itself.”
Not only is slang and hate speech voluminous, but it is ever-shifting. So the task of cataloguing it is a continuous one.
Hatebase uses a combination of human and automated processes to scrape the public web for uses of hate-related terms. “We go out to a bunch of sources — the biggest, as you might imagine, is Twitter — and we pull it all in and turn it over to Hatebrain. It’s a natural language program that goes through the post and returns true, false, or unknown.”
True means it’s pretty sure it’s hate speech — as you can imagine, there are plenty of examples of this. False means no, of course. And unknown means it can’t be sure; perhaps it’s sarcasm, or academic chatter about a phrase, or someone using a word who belongs to the group and is attempting to reclaim it or rebuke others who use it. Those are the values that go out via the API, and users can choose to look up more information or context in the larger database, including location, frequency, level of offensiveness, and so on. With that kind of data you can understand global trends, correlate activity with other events, or simply keep abreast of the fast-moving world of ethnic slurs.
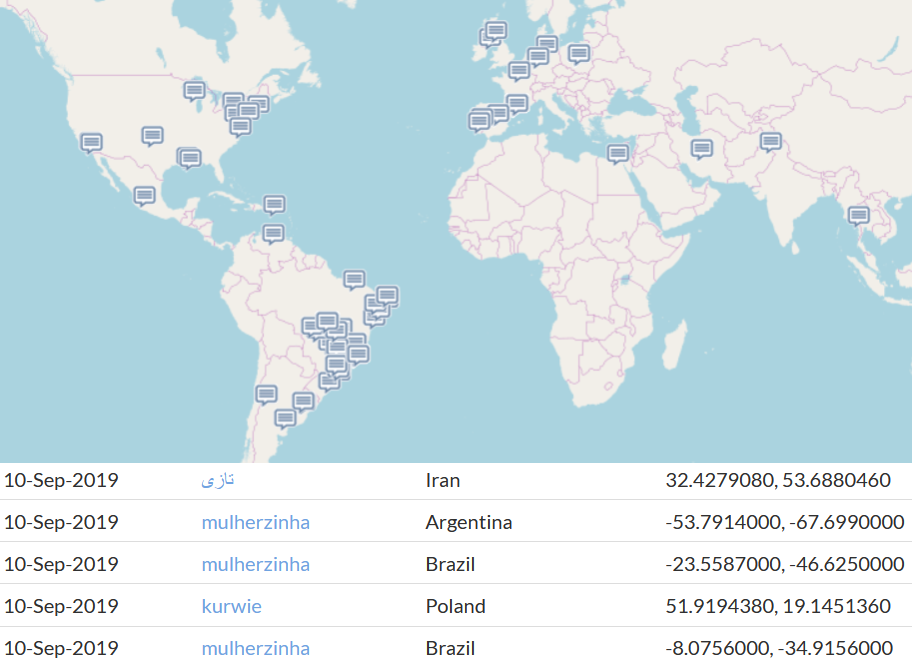
Hate speech being flagged all around the world — these were a handful detected today, along with the latitude and longitude of the IP they came from.
Quinn doesn’t pretend the process is magical or perfect, though. “There are very few 100 percents coming out of Hatebrain,” he explained. “It varies a little from the machine learning approach others use. ML is great when you have an unambiguous training set, but with human speech, and hate speech, which can be so nuanced, that’s when you get bias floating in. We just don’t have a massive corpus of hate speech, because no one can agree on what hate speech is.”
That’s part of the problem faced by companies like Google, Twitter, and Facebook — you can’t automate what can’t be automatically understood.
Fortunately Hatebrain also employs human intelligence, in the form of a corps of volunteers and partners who authenticate, adjudicate, and aggregate the more ambiguous data points.
“We have a bunch of NGOs that partner with us in linguistically diverse regions around the world, and we just launched our ‘citizen linguists’ program, which is a volunteer arm of our company, and they’re constantly updating and approving and cleaning up definitions,” Quinn said. “We place a high degree of authenticity on the data they provide us.”
That local perspective can be crucial for understanding the context of a word. He gave the example of a word in Nigeria, which when used between members of one group means friend, but when used by that group to refer to someone else means uneducated. It’s unlikely anyone but a Nigerian would be able to tell you that. Currently Hatebase covers 95 languages in 200 countries, and they’re adding to that all the time.
Furthermore there are “intensifiers,” words or phrases that are not offensive on their own but serve to indicate whether someone is emphasizing the slur or phrase. Other factors enter into it too, some of which a natural language engine may not be able to recognize because it has so little data concerning them. So in addition to keeping definitions up to date, the team is also constantly working on improving the parameters used to categorize speech Hatebrain encounters.
Building a better database for science and profit
The system just ingested its millionth hate speech sighting (out of perhaps tens times that many phrases evaluated), which sounds simultaneously like a lot and a little. It’s a little because the volume of speech on the internet is so vast that one rather expects even the tiny proportion of it constituting hate speech to add up to millions and millions.
But it’s a lot because no one else has put together a database of this size and quality. A vetted, million-data-point set of words and phrases classified as hate speech or not hate speech is a valuable commodity all on its own. That’s why Hatebase provides it for free to researchers and institutions using it for humanitarian or scientific purposes.
But companies and larger organizations looking to outsource hate speech detection for moderation purposes pay a license fee, which keeps the lights on and allows the free tier to exist.
“We’ve got, I think, four of the world’s ten largest social networks pulling our data. We’ve got the UN pulling data, NGOs, the hyper local ones working in conflict areas. We’ve been pulling data for the LAPD for the last couple years. And we’re increasingly talking to government departments,” Quinn said.
They have a number of commercial clients, many of which are under NDA, Quinn noted, but the most recent to join up did so publicly, and that’s TikTok. As you can imagine, a popular platform like that has a great need for quick, accurate moderation.
In fact it’s something of a crisis, since there are laws coming into play that penalize companies enormous amounts if they don’t promptly remove offending content. That kind of threat really loosens the purse strings; If a fine could be in the tens of millions of dollars, paying a significant fraction of that for a service like Hatebase’s is a good investment.
“These big online ecosystems need to get this stuff off their platforms, and they need to automate a certain percentage of their content moderation,” Quinn said. “We don’t ever think we’ll be able to get rid of human moderation, that’s a ridiculous and unachievable goal; What we want to do is help automation that’s already in place. It’s increasingly unrealistic that every online community under the sun is going to build up their own massive database of multilingual hate speech, their own AI. The same way companies don’t have their own mail server any more, they use Gmail, or they don’t have server rooms, they use AWS — that’s our model, we call ourselves hate speech as a service. About half of us love that term, half don’t, but that really is our model.”
Hatebase’s commercial clients have made the company profitable from day one, but they’re “not rolling in cash by any means.”
“We were nonprofit until we spun out, and we’re not walking away from that, but we wanted to be self-funding,” Quinn said. Relying on the kindness of rich strangers is no way to stay in business, after all. The company is hiring and investing in its infrastructure, but Quinn indicated that they’re not looking to juice growth or anything — just make sure the jobs that need doing have someone to do them.
In the meantime it seems clear to Quinn and everyone else that this kind of information has real value, though it’s rarely simple.
“It’s a really, it’s a really complicated problem. We always grapple with it, you know, in terms of, well, what role does hate speech play? What role does misinformation play? What role do socioeconomics play?” he said. “There’s a great paper that came out of the University of Warwick, they studied the correlation between hate speech and violence against immigrants in Germany over, I want to say, 2015 to 2017. They graph it out. And its peak for peak, you know, valid for Valley. It’s amazing. We don’t do a hell of a lot of analysis — we’re a data provider.”
“But now have like, almost 300 universities pulling the data, and they do those kinds of those kinds of analyses. So that’s very validating for us.”
You can learn more about Hatebase, join the Citizen Linguists or research partnership, or see recent sightings and updates to the database at the company’s website.
Source


